Golang Testing Parallel
本文将介绍 Golang 单元测试的串行运行和并行运行的实现细节,以及在使用 github.com/stretchr/testify/suite 库时,如何控制串行和并行。
基本流程 Basic Procedure
Test Code Scanning, Loading and Test Cases Execution
通常我们会用如下的命令运行单元测试: go test -v goexample/pkg/apiserver,也就是我们运行 package goexample/pkg/apiserver 下的所有单元测试。下面,我们先来分析这个命令的内部流程。
首先 go test 这个命令会扫描 package 下的测试代码信息(名字以 _test.go 结尾的文件),然后会用这些代码信息重新生成一个 main 程序,或者称为 testmain 程序,执行这个程序就是在执行所有的测试用例代码。我们需要先来看一下这里生成 testmain 程序的细节,这个对于理解测试用例的串行和并行是至关重要的。
-
和扫描测试代码信息,以及生成 testmain 有关的代码在 Golang 仓库的 src/cmd/go/internal/load/test.go 文件里。这个文件最下面有一个
testmainTmpl的变量,保存了用于生成 testmain 程序的模板。其中的main函数部分如下:func main() { testing.RegisterCover(testing.Cover{ Mode: , Counters: coverCounters, Blocks: coverBlocks, CoveredPackages: , }) m := testing.MainStart(testdeps.TestDeps{}, tests, benchmarks, examples) .(m) os.Exit(int(reflect.ValueOf(m).Elem().FieldByName("exitCode").Int())) os.Exit(m.Run()) }从这个代码可以看出,首先会会先执行
m := testing.MainStart()以获得一个testing.M对象。随后,如果你定义了TestMain函数,就会执行该函数,否则执行m.Run()。这里的 testing 就是标准库里的 testing 库。 -
上面代码中,传递给
testing.MainStart函数的tests变量是在该模板中定义的的一个[]testing.InternalTest列表,其每个元素就对应测试 package 中的一个TestXxx(t *testing.T)函数 (是文件级的函数,不是 testify/suite 的一个 suite 的方法,相关的代码也是在上面提到的 load/test.go 文件中,就不展开说了)。在通过testing.MainStart()创建testing.M对象时,这些测试用例文件都存放在了testing.M.tests成员中。 -
接下来就是执行
testing.M.Run()方法,在这个方法内,主要是调用 testing 库的runTests函数(下文如无特别说明,所提到的函数都是指 testing 库中的函数)。runTests函数可以认为是一个 package 下的所有用例的执行入口,来看下该函数:func runTests(matchString, tests []InternalTest, deadline time.Time) (ran, ok bool) { // 忽略掉控制运行次数的之类的代码 // ignore the code controlling running times { // In loops. // ctx 用于进行并发控制 // ctx is used to control parallel execution ctx := newTestContext(*parallel, newMatcher(matchString, *match, "-test.run")) ctx.deadline = deadline t := &T{ common: common{ signal: make(chan bool), barrier: make(chan bool), w: os.Stdout, }, context: ctx, } if Verbose() { t.chatty = newChattyPrinter(t.w) } tRunner(t, func(t *T) { for _, test := range tests { t.Run(test.Name, test.F) } // Run catching the signal rather than the tRunner as a separate // goroutine to avoid adding a goroutine during the sequential // phase as this pollutes the stacktrace output when aborting. go func() { <-t.signal }() }) ok = ok && !t.Failed() ran = ran || t.ran } }上述代码的重点有 3 个:
- 这里的
t,是整个 package 的最高级的T对象,其他的t都是它的儿子。我们将这个t称为 t0。 tRunner函数是用于执行一个用例的,它的函数定义如下:func tRunner(t *T, fn func(t *T)),它的主要逻辑是用第一个参数t来执行第二个参数fn,然后在 defer 中处理 panic,以及并发控制等逻辑。func (t *T) Run(name string, f func(t *T)) bool函数表示将第二个参数f作为当前 receivert的儿子用例来执行。
因此,
runTests的逻辑可以简述为:- 先定义 t0。
-
生成 t0 对应的测试用例,就是:
func(t *T) { for _, test := range tests { t.Run(test.Name, test.F) } ... }这里的
tests就是上面提到的TestXxx测试函数,即通常所说的测试用例。因为tRunner主要逻辑就是调用这个匿名函数,因此在这个地方,就会一个接一个的执行测试文件中定义个的TestXxx函数。 - 使用
tRunner执行 t0 的测试用例。这里我可以先说一个结论:如果没有调用t.Parallel(),那么t.Run()的执行是阻塞的,会一直等到一个测试用例,即TestXxx函数执行完成后才返回。所以,默认情况下,go test是串行的执行测试用例的。为什么会这样等我们下面讲到t.Run()的实现时会再说。
- 这里的
到这里,我们就了解了 go test 命令如何扫描测试代码,并且最终是如何调用我们的测试用例的。下面我们要分别看一下 tRunner 和 t.Run 这两个函数的实现细节。
tRunner
函数 func tRunner(t *T, fn func(t *T)) 的基本结构如下:
func tRunner(t *T, fn func(t *T)) {
defer func() {
// handle panic
defer func() {
if didPanic {
return
}
if err != nil {
panic(err)
}
t.signal <- signal // 这个 signal 会让父用例的等待返回,见下文 t.Run 的说明。
}()
// handle subtests
if len(t.sub) > 0 {
// release 相当于释放一个锁,使得子用例可以执行。
t.context.release()
// 关闭这个 channel,表示当前用例的所有逻辑都处理完了,子用例可以开始执行。
close(t.barrier)
// 等待每个子用例执行完成。
for _, sub := range t.sub {
<-sub.signal
}
}
...
}()
fn(t)
}
整个 tRunner 函数的主要部分就两个,首先在函数内调用测试用例 fn,然后在 defer 里处理 panic 以及等待子用例的完成。从上面的代码可以得到如下结论:父用例一定要先执行完,子用例才有机会执行。
t.Run
方法 func (t *T) Run(name string, f func(t *T)) 的基本结构如下:
func (t *T) Run(name string f func(t *T)) bool {
...
// 生成一个新的 t,会集成父亲的`t.common` 部分。这里代码命名有些换乱,其实新的 t 称为 subt 更好。
// 为了描述更清晰,我们统一使用 subt 这个名字来表示子用例。
t = &T{
common: common{
barrier: make(chan bool),
signal: make(chan bool),
name: testName,
parent: &t.common,
level: t.level + 1,
creator: pc[:n],
chatty: t.chatty,
},
context: t.context,
}
...
go tRunner(t, f) // 使用 subt 来运行测试用例 f
if !<-t.signal { // 等待 subt 执行完成
runtime.Goexit()
}
return !t.failed
}
t.Run 的主要逻辑就是生成一个 subt,然后等待 subt 执行完成。这里的等待分为两个情况:
- 默认情况下,
subt会在执行完成后才执行t.signal <- signal操作(见上一小节),所以此时这里是阻塞等待。上面我们也提到了,在最开始的时候,runTests函数里 t0 对应的测试用例就是对每个用例调用t.Run,因此默认情况下,runTests是逐个执行用例的。 - 如果有用例调用了
t.Parallel(),那么这里就会返回(详情见下一章)。所以如果一个 package 里每个用例都调用了t.Parallel(),那么runTests里的 t0 用例就会立刻返回。
接下来,我们看一下 T 这个结构体:
type T struct {
common
isParallel bool
context *testContext // For running tests and subtests.
}
你会发现,在 t.Run 函数里,还有一个需要注意的地方,就是新建的 subt 没有继承父亲 t 的 isParallel 的值,因此一个用例的所有子用例,默认是串行的。
并行流程
Golang 在 1.7 版本增加了子用例的支持,同时也支持了用例的并行执行: https://blog.golang.org/subtests. 官方的这篇 blog 有简述了并行的实现,现在我们从代码上来分析它是如何实现的。
实现并行的关键就是 t.Parallel 函数。上文我们提到,当父用例调用子用例时,即通过 t.Run 方法来执行子用例时,默认情况下会阻塞在 <-subt.signal 这里。但是当子用例调用了 t.Parallel 方法时,这里就会返回。我们可以在 t.Parallel 的代码中看到相关逻辑:
func (t *T) Parallel() {
t.isParallel = true
...
// 将自己加入父亲的 sub 列表中。
t.parent.sub = append(t.parent.sub, t)
...
// 这里直接写入成功,会使得 t.Run() 里的等待返回。
t.signal <- true
// 这里等待父用例调用 close(t.barrier),上面提到了,这个会在 tRunner 的 defer 中调用。
<-t.parent.barrier
// 并发控制,通过这个来控制用例并发数。当并发数不够时,会一直阻塞在这里。
t.context.waitParallel()
...
}
结合上文的相关信息,我们现在知道用例的并行执行是这样进行的:
- 父用例
t的代码中会调用t.Run来执行子用例。 t.Run内会生成子用例subt,然后调用tRunner来执行subt,并且等待subt执行完成(<-subt.signal)。subt在执行的时候调用subt.Parallel():- 其中
subt.signal <- true会导致上面t的<-subt.signal返回。 - 然后
subt会阻塞在<-subt.parent.barrier这里,等待父用例的函数返回(即tRunner里调用的fn(t)返回)。
- 其中
- 父用例
t的函数执行完返回后,会在 defer 里close(t.barrier),以便子用例执行。 - 父用例等待子用例执行完。
重点强调一下,父用例调用子用例后,一定要返回,否则子用例无法执行。上述流程如下图所示:
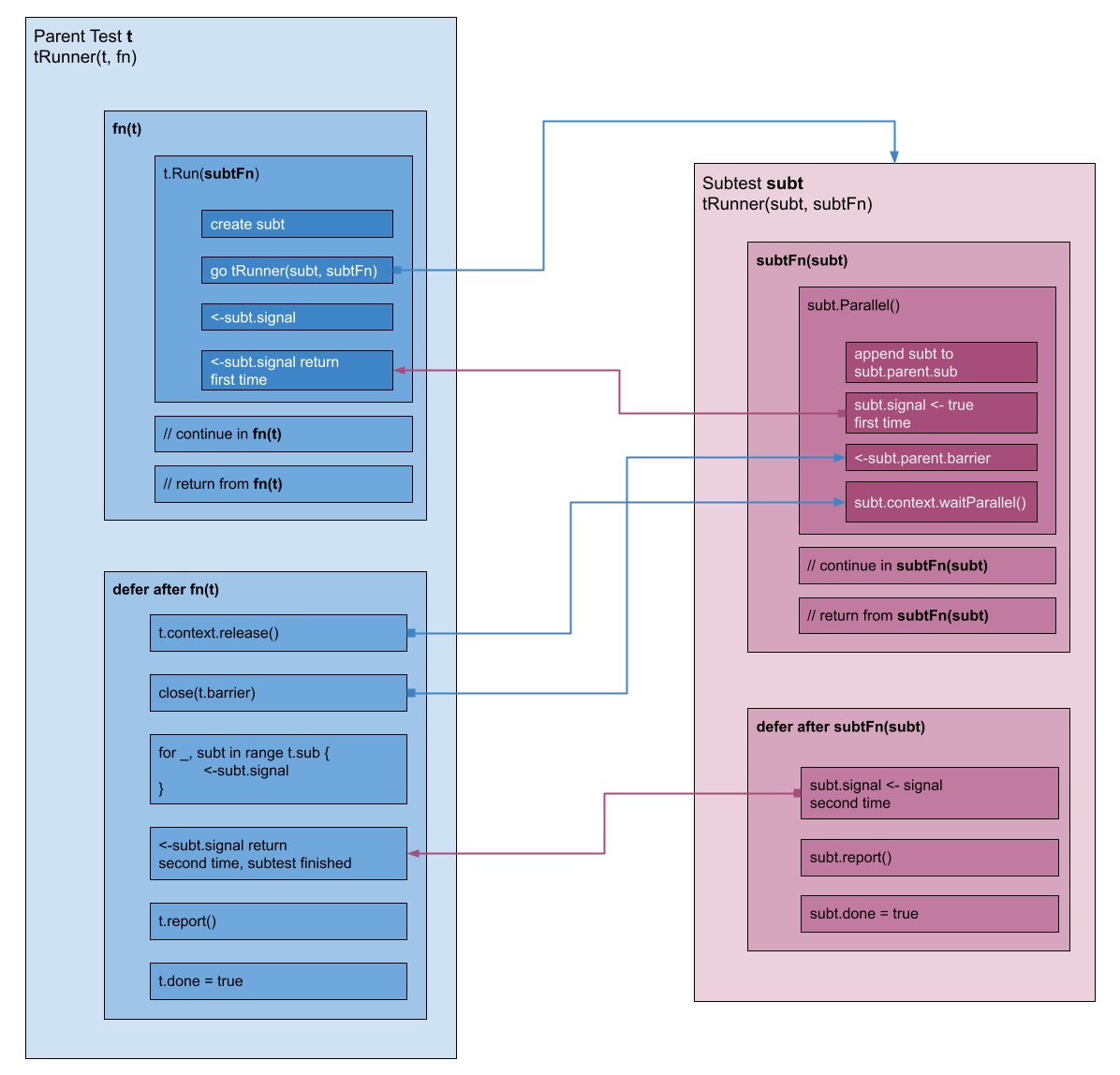
testify/suite 与并行
github.com/stretchr/testify 这个库提供了 suite 功能,可以让我们编写测试用例更加方便。当我们使用这个库时,我们一般是这么写的:
package somename
import (
"testing"
"github.com/stretchr/testify/suite"
)
func TestXxxSuite(t1 *testing.T) {
suite.Run(t, new(xxxSuite))
}
type xxxSuite struct {
}
func (s *xxxSuite) SetupSuite() {
}
func (s *xxxSuite) TearDownSuite() {
}
func (s *xxxSuite) SetupTest() {
}
func (s *xxxSuite) TearDownTest() {
}
func (s *xxxSuite) TestCase1() {
// t1sub1
}
func (s *xxxSuite) TestCase2() {
// t1sub2
}
func TestYyySuite(t2 *testing.T) {
}
我们先来看一下 suite 库执行用例的流程。在上文中,我们已经知道,整个 package 的用例执行入口是 runTests 函数,里面会生成顶级的 t0。t0 在执行时,就会对每个顶级的函数调用 t0.Run() 方法,这个方法里会生成一个新的 subt,用于执行我们的顶级测试函数,在这里就是 TestXxxSuite 和 TestYyySuite,我们将这个 t0 的儿子称为 t1 和 t2,分别对应 TestXxxSuite 和 TestYyySuite。
接下来,我们来分析一下 suite.Run 的实现,通过了解它的实现,我们可以知道 suite 库是如何组织用例的。suite.Run 的基本结构如下:
// Run 函数属于 pacagek github.com/stretchr/suite
func Run(t *testing.T, suite TestingSuite) {
// 扫描 suite 结构体,得到所有的以 Test 开头的方法,这些方法组成该 suite 下的所有用例。
// 遍历每个方法,即每个测试用例
for eachMethod {
// 判断是否需要执行 SetupSuite 方法,这个方法对于整个 suite 只会执行一次。
// 为当前正在处理的方法生成一个 testing.InternalTest 结构体,其中的成员 F 会调用测试用例对应的方法,F 的结构如下:
// F {
// call SetupTest
// call BeforeTest
// call the method
// call AfterTest
// call TearDownTest
// }
}
// 使用 t.Run 方法来执行刚才生成的所有测试用例,这里的 t 是对应 TestXxxSuite 函数
// 等所有用例都返回(这里只是返回,并不是用例执行完,下面会详细说)
// 执行 TearDownSuite
}
在上面的 Run 函数中,使用了前文提到的 t.Run 方法来执行子用例,也就是说会生成下一层的 subt,例如 t1sub1, t2sub2 等,如下图所示:
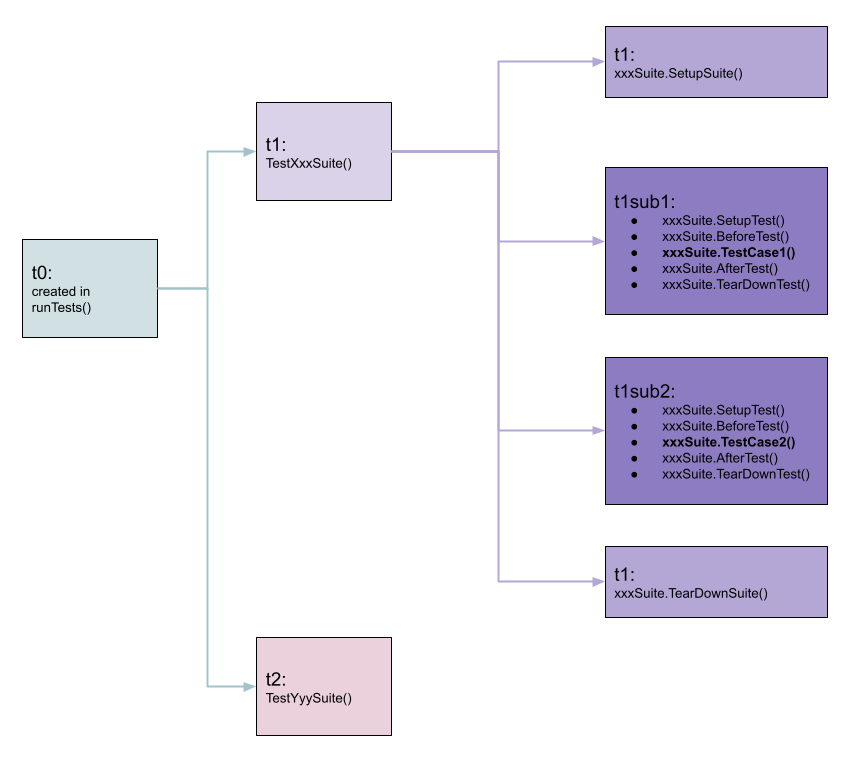
现在我们可以来分析一下使用 suite 库时,如何进行并行测试。首先,串行的流程如下:
runTests创建t0。runTests将每个顶级函数作为子用例来执行,生成t1,t2等。- 顶级函数
TestXxxSuite调用suite.Run函数,为一个 suite 中的每个方法生成一个子用例,然后执行所有的子用例。等待所有的子用例都执行之后,该顶级函数才返回。 - 继续执行下一个顶级函数
TestYyySuite。
总的来说,所有用例都是串行执行的,每次按照顺序执行一个 suite 内的所有用例。
当我们考虑在这个流程中启用并行时,需要考虑如下几个方面的问题:
- 一个 suite 内的每个测试用例是共享同一个 suite 的内存的,所以如果在这些方法上开启并行,那么就得考虑对共享的内存进行保护。
- 如果在一个 suite 内的测试用例上启用并行,那么需要注意,属于其父用例的函数必须执行结束后,这些子用例才会开始执行。所以,
TearDownSuite这个方法就会变成在所有的子用例执行之前就要执行完,这个有点违背接口的含义。 - 不同 suite 之间虽然没有共享 suite 结构体的内存,但是也可能共享其他的全局变量,这就需要业务代码进行一定的调整。
综上所述,在使用 suite 库时,如果要启用并行测试,一个比较可行的策略是: 每个 suite 间启用并行,suite 内则使用串行。具体做法可以参考下面这几个步骤:
- 在
suite.SetupSuite内调用t.Parallel(),使得该 suite 进入并行状态。不过因为 parallel 设置是不传递给子用例的,所以该 suite 的所有子用例还是会串行执行。 - 如果被测试的代码共享了全局变量,那么需要修改被测试代码。
- 一个 suite 内的每个测试用例的配套方法(
SetupTest,BeforeTest,AfterTest,TearDownTest)可以直接访问 suite 内存而不用加锁,因为 suite 内的每个用例都是串行执行的。
示例代码如下:
package somename
import (
"testing"
"github.com/stretchr/testify/suite"
)
func TestXxxSuite(t1 *testing.T) {
suite.Run(t, new(xxxSuite))
}
type xxxSuite struct {
}
func (s *xxxSuite) SetupSuite() {
// Let the suite running in parallel with other suites.
s.T().Parallel()
}
func (s *xxxSuite) TearDownSuite() {
}
func (s *xxxSuite) SetupTest() {
// visit fields of s
}
func (s *xxxSuite) TearDownTest() {
// visit fields of s
}
func (s *xxxSuite) TestCase1() {
// t1sub1
}
func (s *xxxSuite) TestCase2() {
// t1sub2
}
 本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。