beego ORM 和 Golang sql.DB
几个数据结构之间的关系
注册数据库
我们使用如下的方式来将一个数据库注册到 beego ORM 的 default alias 中:
orm.RegisterDatabase("default", dsn, MaxIdleConns, MaxOpenConns)RegisterDataBase() 方法的主要内容是将 orm.alias 对象和 sql.DB,以及对应数据库类型的 dbBaser 对象关联起来。
// RegisterDataBase Setting the database connect params. Use the database driver self dataSource args.
func RegisterDataBase(aliasName, driverName, dataSource string, params ...int) error {
var (
err error
db *sql.DB
al *alias
)
db, err = sql.Open(driverName, dataSource)
...
al, err = addAliasWthDB(aliasName, driverName, db)
if err != nil {
goto end
}
...
return err
}其中 sql.Open 返回一个 *sql.DB 对象。addAliasWithDB() 方法返回 *orm.alias,主要是设置 DbBaser 和 DB 这两个对象。DB 指向 sql.DB,DbBaser 则指向所支持的数据库类型的实现对象。
func addAliasWthDB(aliasName, driverName string, db *sql.DB) (*alias, error) {
al := new(alias)
al.Name = aliasName
al.DriverName = driverName
al.DB = db
if dr, ok := drivers[driverName]; ok {
al.DbBaser = dbBasers[dr]
al.Driver = dr
} else {
return nil, fmt.Errorf("driver name `%s` have not registered", driverName)
}
...
return al, nil
}beego ORM 支持 5 种常用的数据库方言,可以在全局的 dbBasers map 中查到。
dbBasers = map[DriverType]dbBaser{
DRMySQL: newdbBaseMysql(),
DRSqlite: newdbBaseSqlite(),
DROracle: newdbBaseOracle(),
DRPostgres: newdbBasePostgres(),
DRTiDB: newdbBaseTidb(),
}我常用的 Postgres 的实现在 orm/db_postgres.go 里,所依赖的 dbBase 在 orm/db.go 里。
ORM 执行 SQL 语句的过程
一般我们是先调用 NewOrm() 方法获得 orm.Ormer 对象。这个方法会创建一个 orm.orm 对象,主要是设置了 o.alias = al ( al 是上面创建的默认 alias ) 和 o.db = al.DB。即 o.db 是 *sql.DB。
然后,当我们要执行一个查询时,我们一般这么写:
qs := model.orm.QueryTable(new(User))
qs.All(&users)这里的 orm.QueryTable 方法,主要是调用 newQuerySet() 返回一个 QuerySetter interface,本质是一个 *querySet。
// return a QuerySeter for table operations.
// table name can be string or struct.
// e.g. QueryTable("user"), QueryTable(&user{}) or QueryTable((*User)(nil)),
func (o *orm) QueryTable(ptrStructOrTableName interface{}) (qs QuerySeter) {
name := ""
if table, ok := ptrStructOrTableName.(string); ok {
name = snakeString(table)
if mi, ok := modelCache.get(name); ok {
qs = newQuerySet(o, mi)
}
} else {
name = getFullName(indirectType(reflect.TypeOf(ptrStructOrTableName)))
if mi, ok := modelCache.getByFullName(name); ok {
qs = newQuerySet(o, mi)
}
}
if qs == nil {
panic(fmt.Errorf("<Ormer.QueryTable> table name: `%s` not exists", name))
}
return
}
func newQuerySet(orm *orm, mi *modelInfo) QuerySeter {
o := new(querySet)
o.mi = mi
o.orm = orm
return o
}
// real query struct
type querySet struct {
mi *modelInfo
cond *Condition
related []string
relDepth int
limit int64
offset int64
groups []string
orders []string
distinct bool
orm *orm
}最后,我们执行的 All() 等查询方法,大概是下面这样的:
func (o *querySet) All(container interface{}, cols ...string) (int64, error) {
return o.orm.alias.DbBaser.ReadBatch(o.orm.db, o, o.mi, o.cond, container, o.orm.alias.TZ, cols)
}所以要执行一个 All(),其实是要到 db_postgres.go 的 dbBasePostgres 里执行 ReadBatch,也就是在 orm/db.go 的 dbBase 的方法:
func (d *dbBase) ReadBatch(q dbQuerier, qs *querySet, mi *modelInfo, cond *Condition, container interface{}, tz *time.Location, cols []string) (int64, error) {
val := reflect.ValueOf(container)
ind := reflect.Indirect(val)
...
query := fmt.Sprintf("%s %s FROM %s%s%s T0 %s%s%s%s%s", sqlSelect, sels, Q, mi.table, Q, join, where, groupBy, orderBy, limit)
var rs *sql.Rows
r, err := q.Query(query, args...)
if err != nil {
return 0, err
}
rs = r
...
return cnt, nil
}这里关注第一个参数 q dbQuerier,dbQuerier 其实就是确定了需要使用 interface,这些是 *sql.DB 支持的方法的一个子集,ORM 只需要用到这些方法。
// db querier
type dbQuerier interface {
Prepare(query string) (*sql.Stmt, error)
Exec(query string, args ...interface{}) (sql.Result, error)
Query(query string, args ...interface{}) (*sql.Rows, error)
QueryRow(query string, args ...interface{}) *sql.Row
}到这里,可以简单总结一下通过 ORM 进行数据库查询的主要过程:
- ORM 根据你注册的 ORM 对象以及你指定的 DB alias 生成要执行的 SQL。这些主要由各种
dbBaser来实现,参考 orm/db_postgres.go 和 orm/db.go。 - ORM 生成了 SQL 之后,调用了
*sql.DB.Query()方法来执行 SQL。 sql.DB在执行查询的时候,则需要依赖于注册的 db driver 来实现,例如 Postgres 的 github.com/lib/pq。这一部分本文就不展开说了。- 得到查询结果之后,再处理成 ORM 对象。
关系图
根据上面的代码分析,可以画一张简单的关系图:
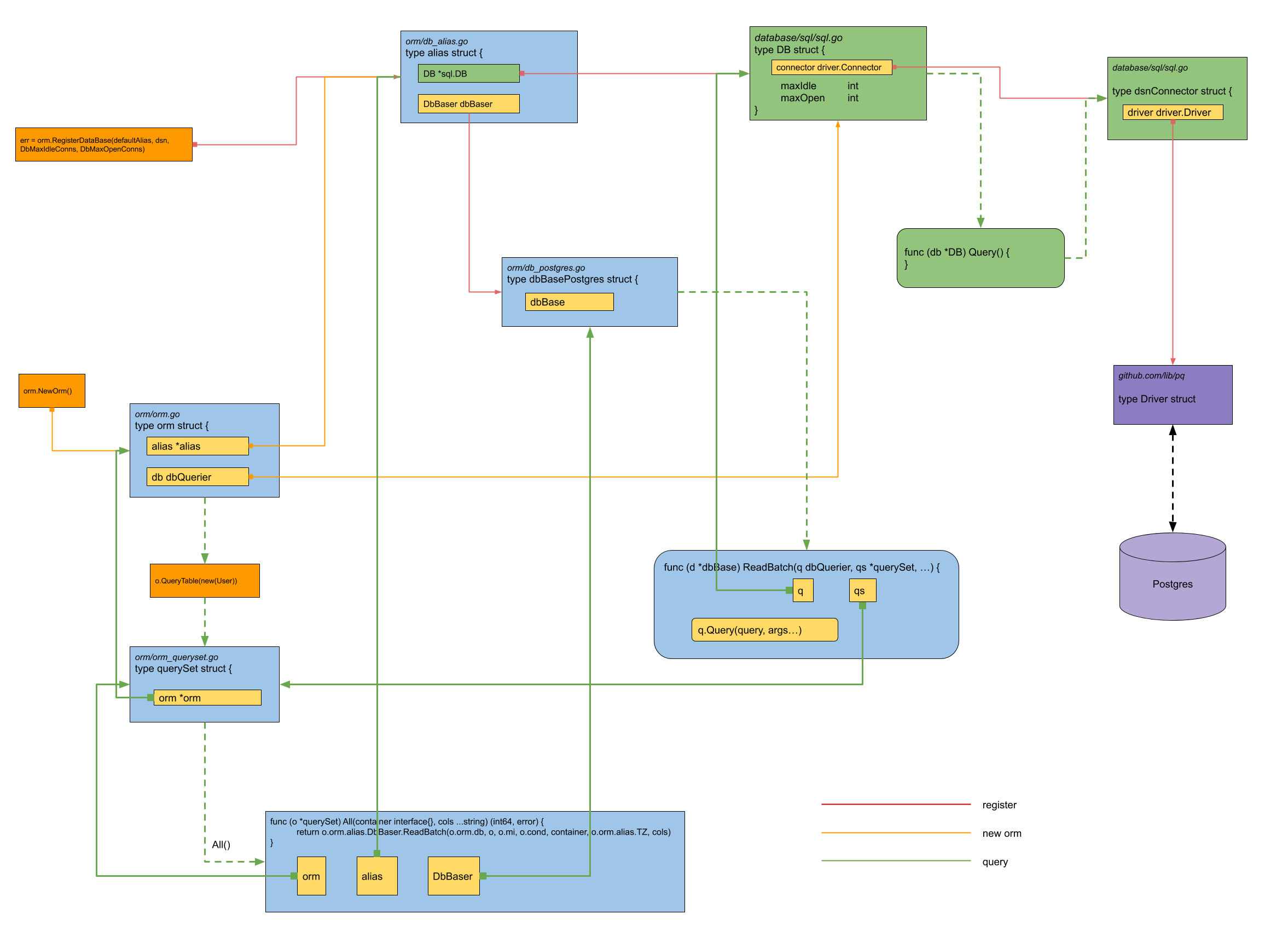
MaxOpenConns and MaxIdleConns
当我们注册一个 alias 的时候,除了 dsn,还会传递参数:MaxOpenConns 和 MaxIdleConns。这两个参数在 beego ORM 中并没有直接使用,而是为了传递给 sql.DB 对象。你可以看到 ORM 代码中调用了 sql.DB 的 SetMaxIdleConns() 和 SetMaxOpenConns() 两个方法。
这两个参数最终会保存在 sql.DB 中:
type DB struct {
...
connector driver.Connector
numOpen int // number of opened and pending open connections
maxIdle int // zero means defaultMaxIdleConns; negative means 0
maxOpen int // <= 0 means unlimited
...
}这两个参数的作用是:
maxIdle,MaxIdleConns: 控制最大空闲连接数。maxOpen,MaxOpenConns: 控制最大连接数。
数据库连接的创建和释放
为了理解 MaxIdleConns 和 MaxOpenConns,我们先来看一下连接的创建和释放的过程。当我们调用到 sql.DB.Query() 的时候,它会先调用 DB.conn() 方法来获取一个连接:
创建连接
// Query executes a query that returns rows, typically a SELECT.
// The args are for any placeholder parameters in the query.
func (db *DB) Query(query string, args ...interface{}) (*Rows, error) {
return db.QueryContext(context.Background(), query, args...)
}
func (db *DB) query(ctx context.Context, query string, args []interface{}, strategy connReuseStrategy) (*Rows, error) {
dc, err := db.conn(ctx, strategy)
if err != nil {
return nil, err
}
return db.queryDC(ctx, nil, dc, dc.releaseConn, query, args)
}DB.conn() 方法主要做了如下的事情:
- 如果找不到 cache 的 conn,就会尝试建立一个新的 conn。
- 判断
db.numOpen是否超过了db.maxOpen,如果超过了,就挂起等待有连接释放或者关闭。 - 否则,就创建一个新的 conn,然后
db.numOpen++。
创建连接的方式,主要是调用驱动的方法,不在本文的范围内讨论。DB.conn() 方法如果成功,会返回一个 *driverConn 对象,这个对象代表数据库连接。
释放连接
当一个连接要被释放时,也就是 *driverConn 对象要被释放时,这个对象的 releaseConn() 方法会被调用(上面的 queryDC() 方法的第四个参数就是这个 releaseConn() 方法:
// driverConn wraps a driver.Conn with a mutex, to
// be held during all calls into the Conn. (including any calls onto
// interfaces returned via that Conn, such as calls on Tx, Stmt,
// Result, Rows)
type driverConn struct {
db *DB
createdAt time.Time
sync.Mutex // guards following
ci driver.Conn
closed bool
finalClosed bool // ci.Close has been called
openStmt map[*driverStmt]bool
lastErr error // lastError captures the result of the session resetter.
// guarded by db.mu
inUse bool
onPut []func() // code (with db.mu held) run when conn is next returned
dbmuClosed bool // same as closed, but guarded by db.mu, for removeClosedStmtLocked
}
func (dc *driverConn) releaseConn(err error) {
dc.db.putConn(dc, err, true)
}其中的 dc.db.putConn 方法如下:
// putConn adds a connection to the db's free pool.
// err is optionally the last error that occurred on this connection.
func (db *DB) putConn(dc *driverConn, err error, resetSession bool) {
db.mu.Lock()
if !dc.inUse {
if debugGetPut {
fmt.Printf("putConn(%v) DUPLICATE was: %s\n\nPREVIOUS was: %s", dc, stack(), db.lastPut[dc])
}
panic("sql: connection returned that was never out")
}
if debugGetPut {
db.lastPut[dc] = stack()
}
dc.inUse = false
for _, fn := range dc.onPut {
fn()
}
dc.onPut = nil
if err == driver.ErrBadConn {
// Don't reuse bad connections.
// Since the conn is considered bad and is being discarded, treat it
// as closed. Don't decrement the open count here, finalClose will
// take care of that.
db.maybeOpenNewConnections()
db.mu.Unlock()
dc.Close()
return
}
if putConnHook != nil {
putConnHook(db, dc)
}
if db.closed {
// Connections do not need to be reset if they will be closed.
// Prevents writing to resetterCh after the DB has closed.
resetSession = false
}
if resetSession {
if _, resetSession = dc.ci.(driver.SessionResetter); resetSession {
// Lock the driverConn here so it isn't released until
// the connection is reset.
// The lock must be taken before the connection is put into
// the pool to prevent it from being taken out before it is reset.
dc.Lock()
}
}
added := db.putConnDBLocked(dc, nil)
db.mu.Unlock()
if !added {
if resetSession {
dc.Unlock()
}
dc.Close()
return
}
if !resetSession {
return
}
select {
default:
// If the resetterCh is blocking then mark the connection
// as bad and continue on.
dc.lastErr = driver.ErrBadConn
dc.Unlock()
case db.resetterCh <- dc:
}
}这里的重点是 added := db.putConnDBLocked(dc, nil) 这行。如果这里返回的 added == false,那么这个连接就会被关闭,否则就会保留。
// Satisfy a connRequest or put the driverConn in the idle pool and return true
// or return false.
// putConnDBLocked will satisfy a connRequest if there is one, or it will
// return the *driverConn to the freeConn list if err == nil and the idle
// connection limit will not be exceeded.
// If err != nil, the value of dc is ignored.
// If err == nil, then dc must not equal nil.
// If a connRequest was fulfilled or the *driverConn was placed in the
// freeConn list, then true is returned, otherwise false is returned.
func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
if db.closed {
return false
}
if db.maxOpen > 0 && db.numOpen > db.maxOpen {
return false
}
if c := len(db.connRequests); c > 0 {
var req chan connRequest
var reqKey uint64
for reqKey, req = range db.connRequests {
break
}
delete(db.connRequests, reqKey) // Remove from pending requests.
if err == nil {
dc.inUse = true
}
req <- connRequest{
conn: dc,
err: err,
}
return true
} else if err == nil && !db.closed {
if db.maxIdleConnsLocked() > len(db.freeConn) {
db.freeConn = append(db.freeConn, dc)
db.startCleanerLocked()
return true
}
db.maxIdleClosed++
}
return false
}
func (db *DB) maxIdleConnsLocked() int {
n := db.maxIdle
switch {
case n == 0:
// TODO(bradfitz): ask driver, if supported, for its default preference
return defaultMaxIdleConns
case n < 0:
return 0
default:
return n
}
}这个方法要做几个事情:
- 如果
db.numOpen > db.maxOpen,那么说明打开的连接数已经超过上限,返回false。 - 如果有 goroutine 正在等待请求,那么就会将当前连接分配给那个 goroutine,返回
true。 - 如果没有 goroutine 正在等待请求,就会判断空闲数量是否达到上限,如果还没有达到,那么就会将连接加入到空闲列表,返回
true。否则,就会返回false。
那么 releaseConn() 什么时候会被调用?这个我们需要看两个地方的代码,首先是 sql.DB.queryDC() 方法的最后一部分:
func (db *DB) queryDC(ctx, txctx context.Context, dc *driverConn, releaseConn func(error), query string, args []interface{}) (*Rows, error) {
...
// Note: ownership of ci passes to the *Rows, to be freed
// with releaseConn.
rows := &Rows{
dc: dc,
releaseConn: releaseConn,
rowsi: rowsi,
closeStmt: ds,
}
rows.initContextClose(ctx, txctx)
return rows, nil
}这个方法返回的 *sql.Rows 对象是查询的行对象,其中的 releaseConn 对象就被赋值为 driverConn.releaseConn()。接下来,再看下 ORM 里的 ReadBatch() 方法:
var rs *sql.Rows
r, err := q.Query(query, args...)
if err != nil {
return 0, err
}
rs = r
refs := make([]interface{}, colsNum)
for i := range refs {
var ref interface{}
refs[i] = &ref
}
defer rs.Close()当我们从这个方法返回时,也就是我们调用的 querySet.All() 方法返回时,*sql.Rows.Close() 会被调用,其中会调用 releaseConn()。
小结
maxIdle表示允许的最大空闲连接,< 0表示不允许空闲连接,== 0表示允许两个空闲连接,> 0表示允许指定的空闲连接。maxOpen表示允许的最大连接数,<= 0表示不限制连接数。- 在 beego ORM 的实现中,一次查询结束之后,就会释放掉连接。
另外,设置的接口中会保证 maxOpen >= maxIdle。
 本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。